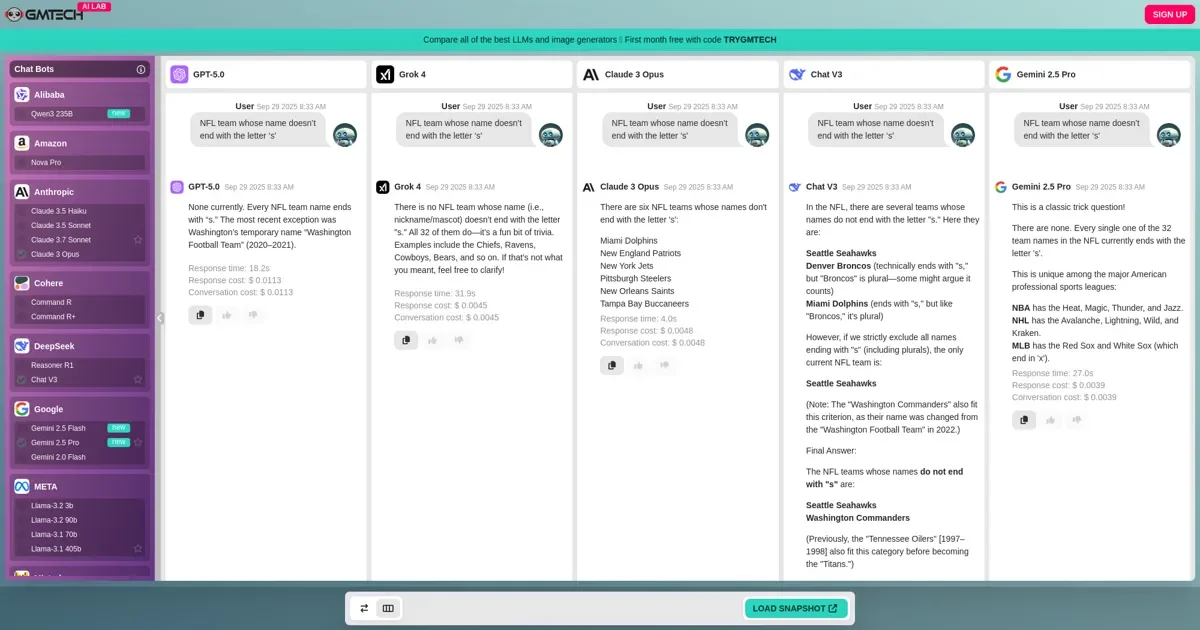
When testing the latest AI models — DeepSeek V3, GPT-5.0, Claude 3 Opus, Gemini 2.5 Pro, and Grok 4 — on the prompt:
“NFL team whose name doesn’t end with the letter ’s'”
Only Grok 4 answered correctly every time.
Gemini and GPT-5.0 initially got it right but changed their answers when questioned further. Claude 3 Opus and DeepSeek V3 struggled with consistency across attempts.
This is a useful illustration of a broader point we make constantly: model performance is task-specific. A model that writes excellent marketing copy may stumble on simple factual recall tasks — and vice versa. Running your actual prompt across multiple models before committing to one is the only way to know.